1. Introduction¶
Machine learning is a subset of artificial intelligence in the field of computer science that often uses statistical techniques to give computers the ability to learn (i.e., progressively improve performance on a specific task) with data, without being explicitly programmed. Machine learning is the design and study of software artifacts that use past experience to make future decisions. It is the study of programs that learn from data. The fundamental goal of machine learning is to generalize, or to induce an unknown rule from examples of the rule’s application. Machine learning systems are often described as learning from experience either with or without supervision from humans.
The Basic three different learning styles in machine learning algorithms:
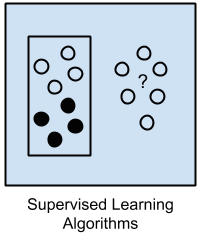
1.1. Supervised Learning¶
A model is prepared through a training process in which it is required to make predictions and is corrected when those predictions are wrong. The training process continues until the model achieves a desired level of accuracy on the training data. A program predicts an output for an input by learning from pairs of labeled inputs and outputs, the program learns from examples of the right answers.
- Input data is called training data and has a known label or result such as spam/not-spam or a stock price at a time.
- Example problems are classification and regression.
- Example algorithms include Logistic Regression and the Back Propagation Neural Network.
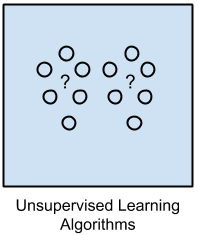
1.2. Unsupervised Learning¶
A model is prepared by deducing structures present in the input data. This may be to extract general rules. It may be through a mathematical process to systematically reduce redundancy, or it may be to organize data by similarity. A program does not learn from labeled data. Instead, it attempts to discover patterns in the data.
- Input data is not labeled and does not have a known result.
- Example problems are clustering, dimensionality reduction and association rule learning.
- Example algorithms include: the Apriori algorithm and k-Means.
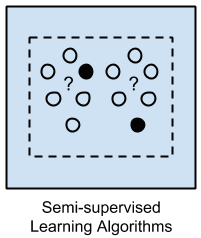
1.3. Semi-Supervised Learning¶
There is a desired prediction problem but the model must learn the structures to organize the data as well as make predictions. Semi-supervised learning problems, make use of both supervised and unsupervised data; these problems are located on the spectrum between supervised and unsupervised learning
- Input data is a mixture of labeled and unlabeled examples.
- Example problems are classification and regression.
- Example algorithms are extensions to other flexible methods that make assumptions about how to model the unlabeled data.
1.4. Key Terms¶
1.4.1. Model¶
A machine learning model can be a mathematical representation of a real-world process. To generate a machine learning model you will need to provide training data to a machine learning algorithm to learn from.
1.4.2. Algorithm¶
Machine Learning algorithm is the hypothesis set that is taken at the beginning before the training starts with real-world data. When we say Linear Regression algorithm, it means a set of functions that define similar characteristics as defined by Linear Regression and from those set of functions we will choose one function that fits the most by the training data.
1.4.3. Training¶
While training for machine learning, you pass an algorithm with training data. The learning algorithm finds patterns in the training data such that the input parameters correspond to the target. The output of the training process is a machine learning model which you can then use to make predictions. This process is also called “learning”.
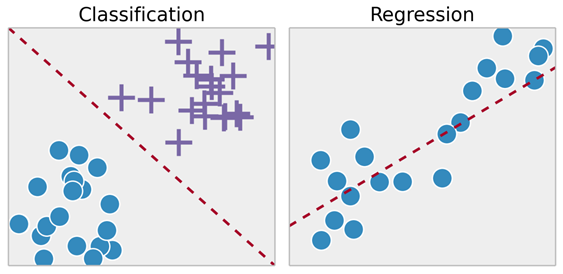
1.4.4. Regression¶
Regression techniques are used when the output is real-valued based on continuous variables. For example, any time series data. This technique involves fitting a line.
1.4.5. Classification¶
In classification, you will need to categorize data into predefined classes. For example, an email can either be ‘spam’ or ‘not spam’.
1.4.6. Target¶
The target is whatever the output of the input variables. It could be the individual classes that the input variables maybe mapped to in case of a classification problem or the output value range in a regression problem. If the training set is considered then the target is the training output values that will be considered.
1.4.7. Feature¶
Features are individual independent variables that act as the input in your system. Prediction models use features to make predictions. New features can also be obtained from old features using a method known as ‘feature engineering’. More simply, you can consider one column of your data set to be one feature. Sometimes these are also called attributes. And the number of features are called dimensions.
1.4.8. Label¶
Labels are the final output. You can also consider the output classes to be the labels. When data scientists speak of labeled data, they mean groups of samples that have been tagged to one or more labels.
1.4.9. Overfitting¶
An important consideration in machine learning is how well the approximation of the target function that has been trained using training data, generalizes to new data. Generalization works best if the signal or the sample that is used as the training data has a high signal to noise ratio. If that is not the case, generalization would be poor and we will not get good predictions. A model is overfitting if it fits the training data too well and there is a poor generalization of new data.
1.4.10. Regularization¶
Regularization is the method to estimate a preferred complexity of the machine learning model so that the model generalizes and the over-fit/under-fit problem is avoided. This is done by adding a penalty on the different parameters of the model thereby reducing the freedom of the model.
1.4.11. Parameter and Hyper-Parameter¶
Parameters are configuration variables that can be thought to be internal to the model as they can be estimated from the training data. Algorithms have mechanisms to optimize parameters. On the other hand, hyperparameters cannot be estimated from the training data. Hyperparameters of a model are set and tuned depending on a combination of some heuristics.
Citations
Footnotes
References